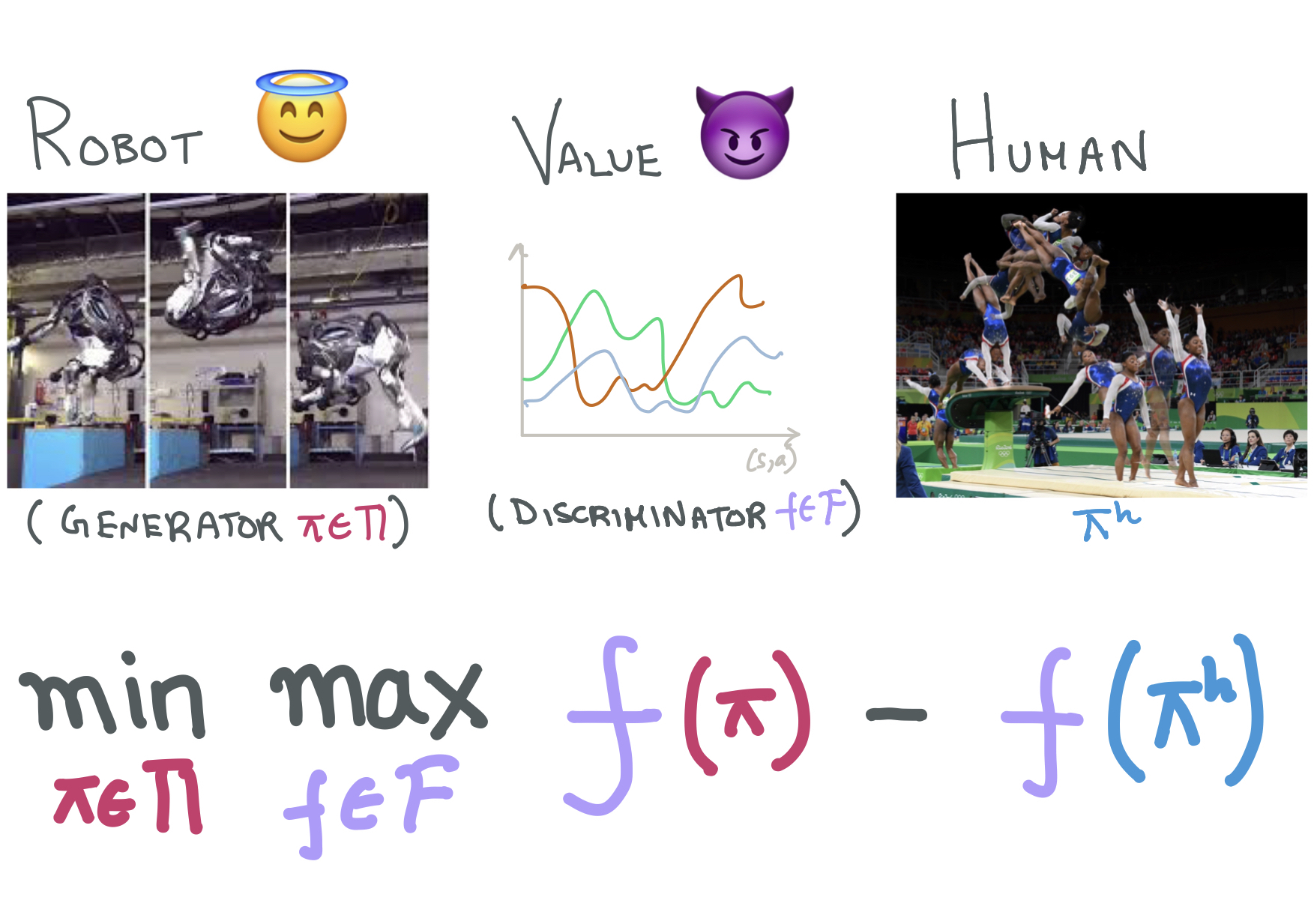Research
We work on interactive AI agents that self-align through few-shot interactions with humans and their environment. Our research focuses on reinforcement learning, imitation learning and foundation models for robotics, agents and code generation.
Projects
|
|
Multi-Turn Code Generation Through Single-Step Rewards
Arnav Kumar Jain*, Gonzalo Gonzalez-Pumariega*, Wayne Chen, Alexander M Rush, Wenting Zhao†, Sanjiban Choudhury† paper / website μCode is a simple and scalable method for multi-turn code generation leveraging learned verifiers. |
|
|
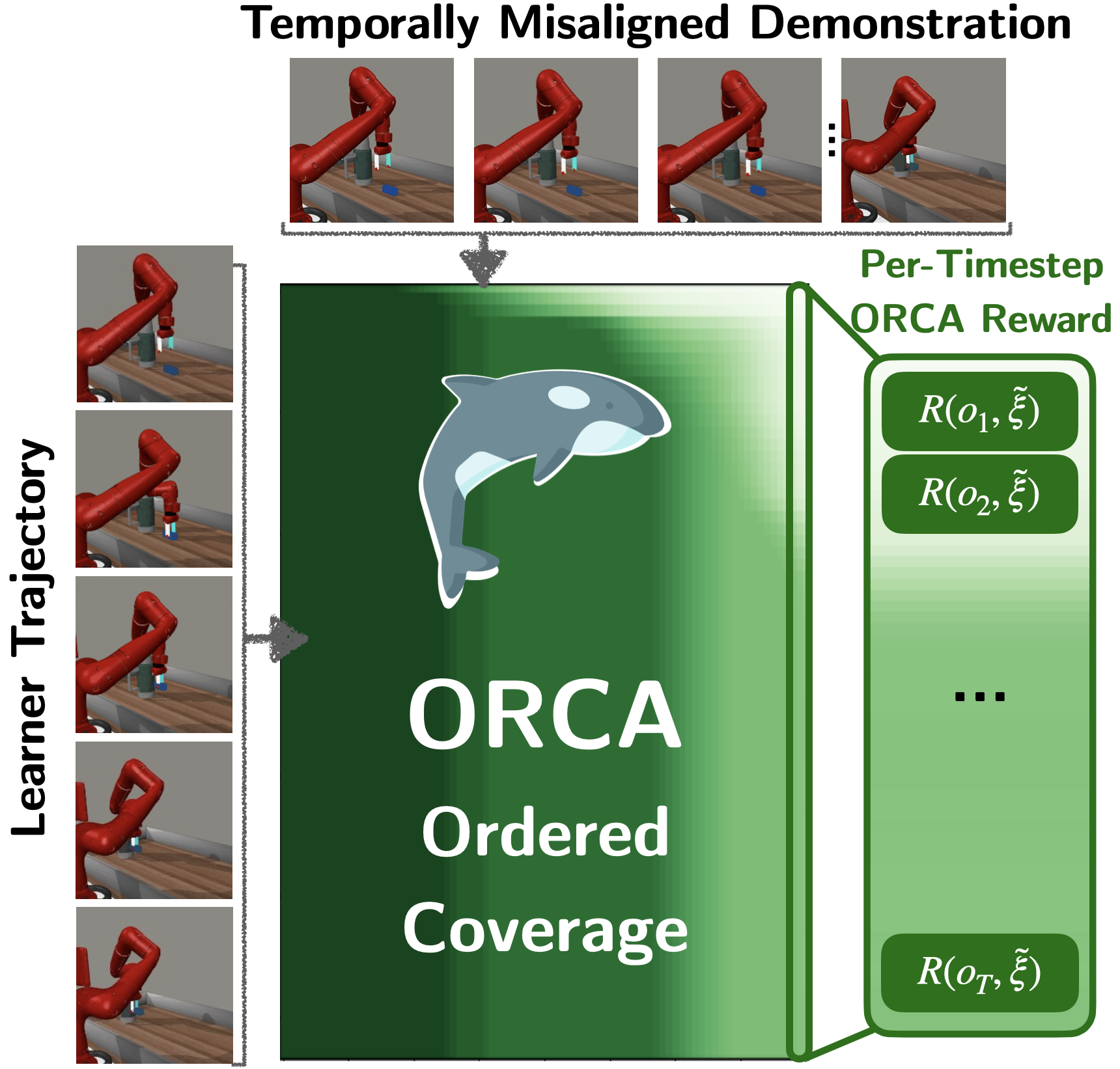
Imitation Learning from a Single Temporally Misaligned Video
William Huey*, Huaxiaoyue Wang*, Anne Wu, Yoav Artzi, Sanjiban Choudhury paper ORCA (ORdered Coverage Alignment) formulates rewards as an ordered coverage problem, enabling robots to learn from a single temporally misaligned video demonstration. |
|
|
Motion Tracks: A Unified Representation for Human-Robot Transfer in Few-Shot Imitation Learning
Juntao Ren, Priya Sundaresan, Dorsa Sadigh, Sanjiban Choudhury, Jeannette Bohg International Conference on Robotics and Automation (ICRA), 2025 paper / website Motion-Track Policy (MT-PI) presents a unified action space by representing actions as 2D trajectories on an image, enabling the robots to directly imitate from cross-embodiment datasets. |
|
|
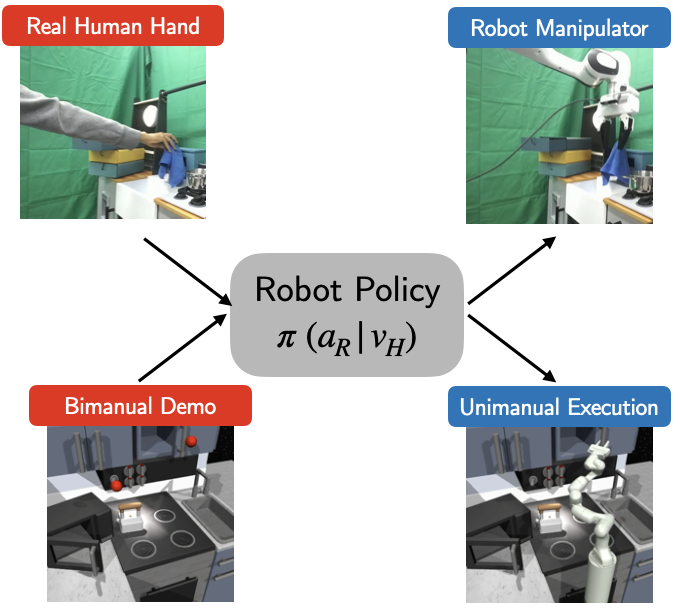
One-Shot Imitation under Mismatched Execution
Kushal Kedia, Prithwish Dan, Angela Chao, Maximus Adrian Pace, Sanjiban Choudhury International Conference on Robotics and Automation (ICRA), 2025 paper / website RHyME introduces a new framework that enables robots to learn from watching human demonstrations even when there are differences in execution styles. |
|
|
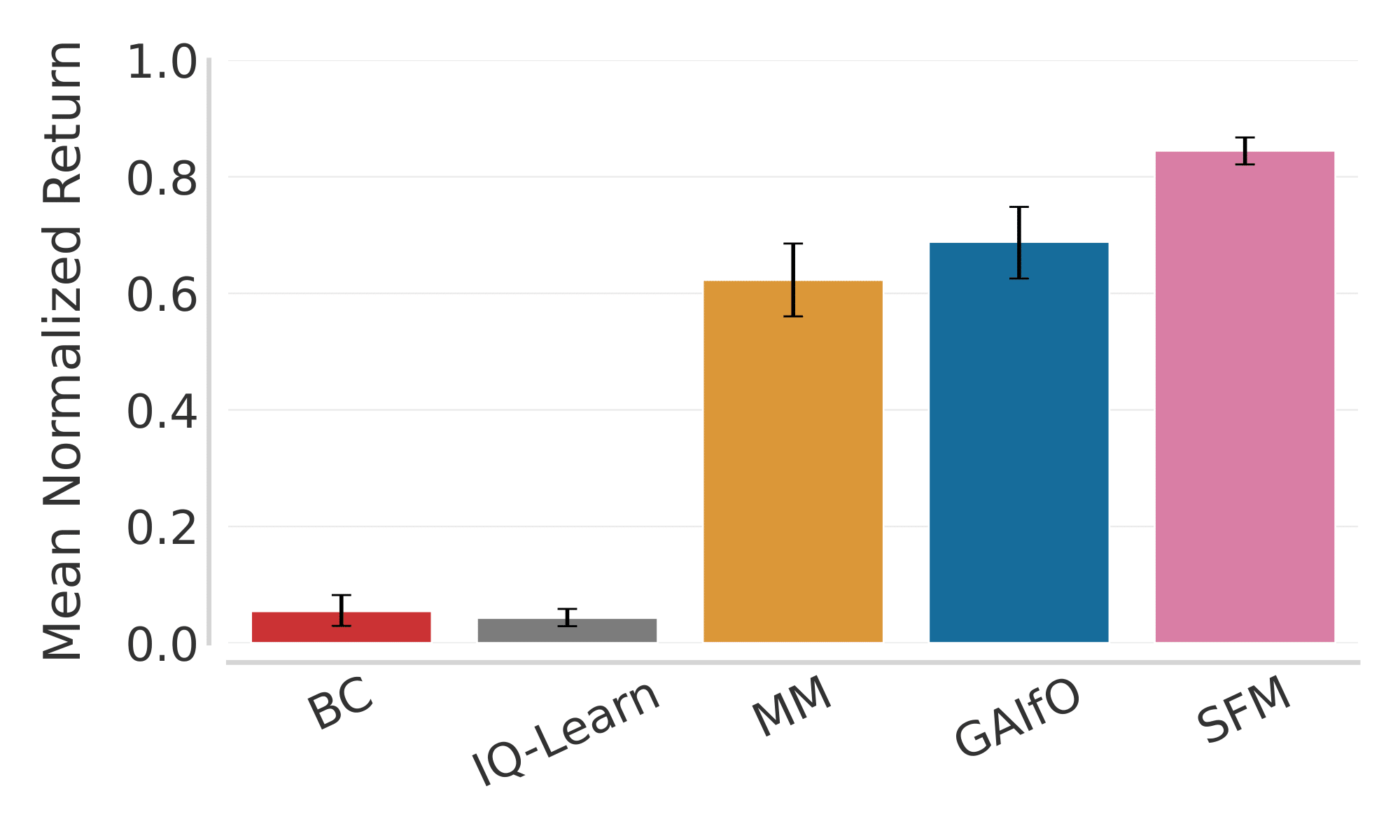
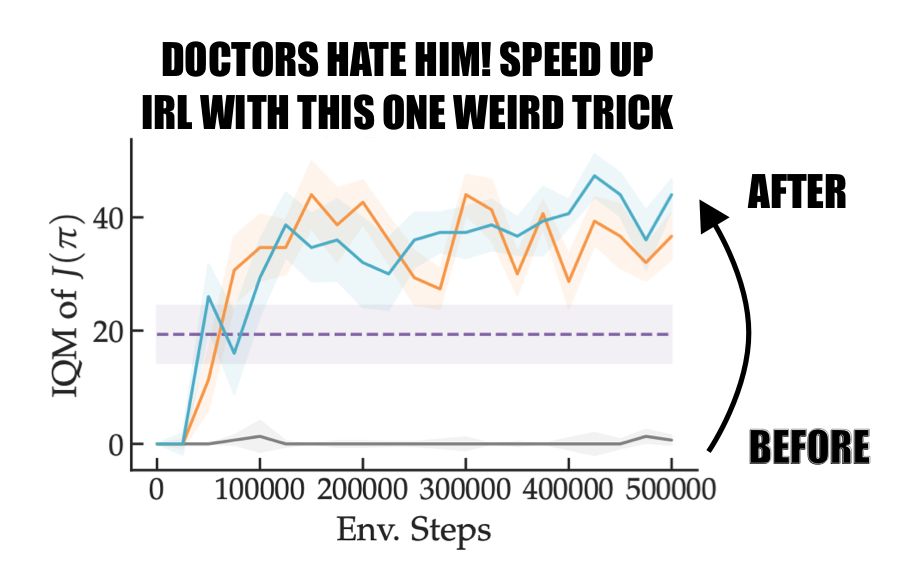
Non-Adversarial Inverse Reinforcement Learning via Successor Feature Matching
Arnav Kumar Jain, Harley Wiltzer, Jesse Farebrother, Irina Rish, Glen Berseth, Sanjiban Choudhury International Conference on Learning Representations (ICLR), 2025 paper / website SFM (Successor Feature Matching) presents a non-adversarial approach for inverse reinforcement learning (IRL) and can learn from state-only demonstrations. |
|
|
Robotouille: An Asynchronous Planning Benchmark for LLM Agents
Gonzalo Gonzalez-Pumariega, Leong Su Yean, Neha Sunkara, Sanjiban Choudhury International Conference on Learning Representations (ICLR), 2025 paper / website Robotouille is a challenging benchmark that tests LLM agents synchronous and asynchronous planning capabilities through diverse long-horizon tasks and time delays. |
|
|
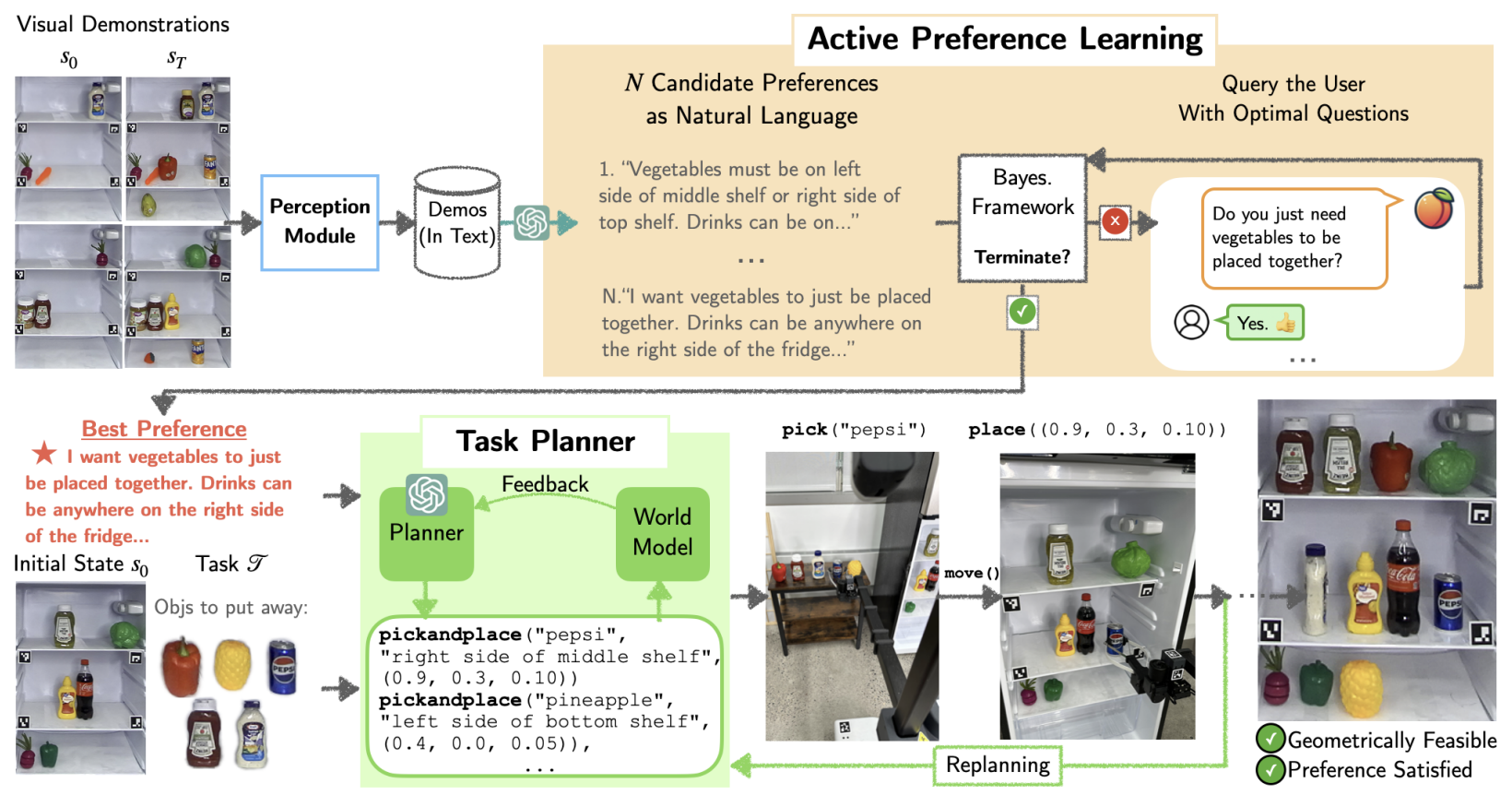
APRICOT: Active Preference Learning and Constraint-Aware Task Planning with LLMs
Yuki Wang, Nathaniel Chin, Gonzalo Gonzalez-Pumariega, and Xiangwan Sun, Neha Sunkara, Maximus Adrian Pace, Jeannette Bohg, Sanjiban Choudhury Conference on Robot Learning (CoRL), 2024 paper / website APRICOT combines the generative ability of LLMs with Bayesian active preference learning, allowing robots to interactively query users to reduce uncertainty. |
|
|
MOSAIC: A Modular System for Assistive and Interactive Cooking
Yuki Wang*, Kushal Kedia*, Juntao Ren*, Rahma Abdullah, Atiksh Bhardwaj, Angela Chao, Kelly Y Chen, Nathaniel Chin, Prithwish Dan, Xinyi Fan, Gonzalo Gonzalez-Pumariega, Aditya Kompella, Maximus Adrian Pace, Yash Sharma, Xiangwan Sun, Neha Sunkara, Sanjiban Choudhury Conference on Robot Learning (CoRL), 2024 paper / website MOSAIC combines large pre-trained models for general tasks with task-specific modules to enable collaborative cooking. |
|
|
Hybrid Inverse Reinforcement Learning
Juntao Ren, Gokul Swamy, Zhiwei Steven Wu, J. Andrew Bagnell, Sanjiban Choudhury International Conference on Machine Learning (ICML), 2024 paper website Hybrid IRL trains policies on a mixture of online and expert data to mitigate exploration. |
|
|
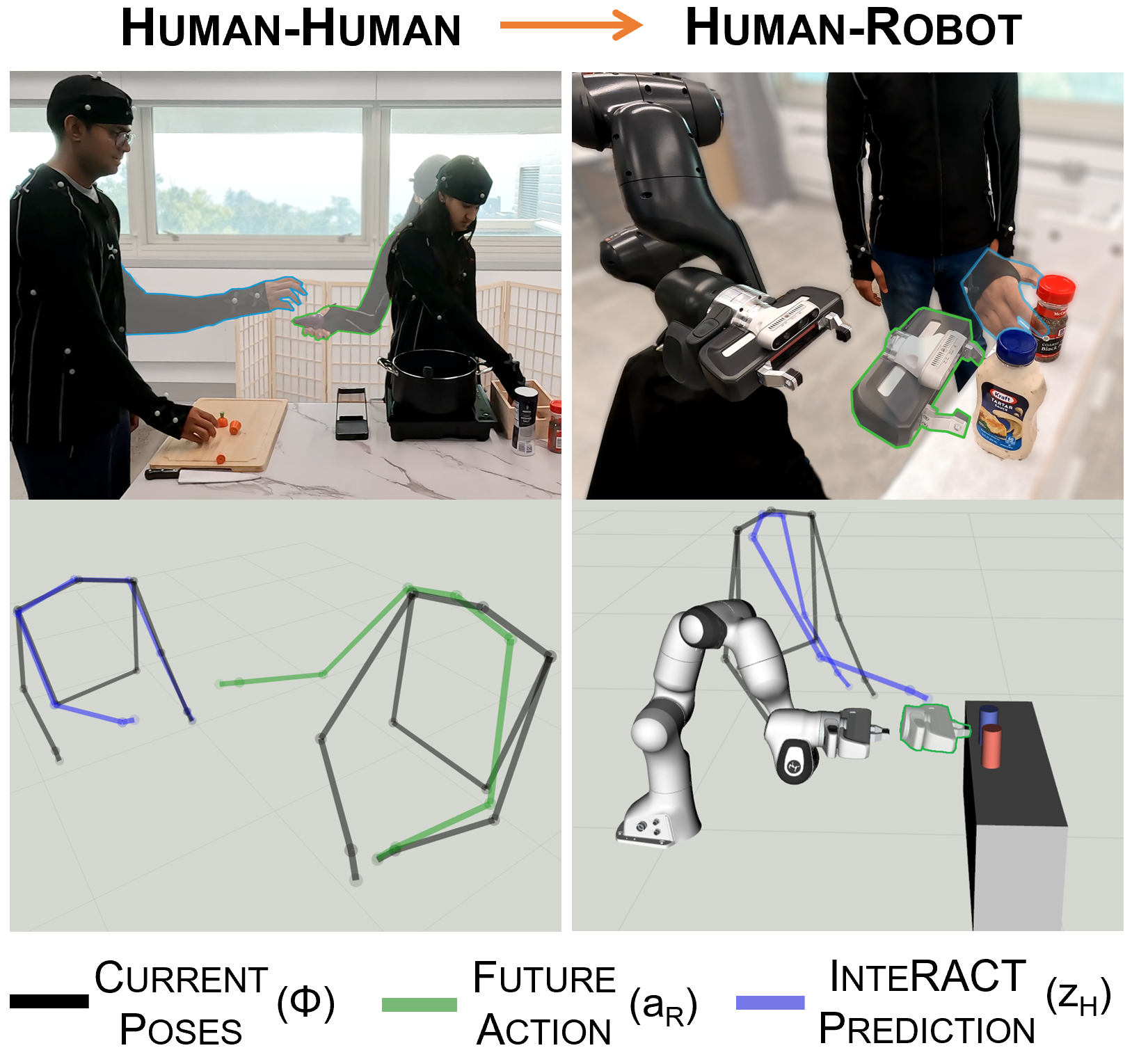
InteRACT: Transformer Models for Human Intent Prediction Conditioned on Robot Actions
Kushal Kedia, Atiksh Bhardwaj, Prithwish Dan, Sanjiban Choudhury International Conference on Robotics and Automation (ICRA), 2024 paper / website Interact, predicts human intent conditioned on future robot actions for collaborative manipulation. |
|
|
Demo2Code: From Summarizing Demonstrations to Synthesizing Code via Extended Chain-of-Thought
Yuki Wang, Gonzalo Gonzalez-Pumariega, Yash Sharma, Sanjiban Choudhury Advances in Neural Information Processing Systems (NeurIPS), 2023 paper / website Demo2Code leverages LLMs to translate demonstrations to robot task code via an extended chain-of-thought that recursively summarizes demos to specification, and recursively expands specification to code. |
|
|
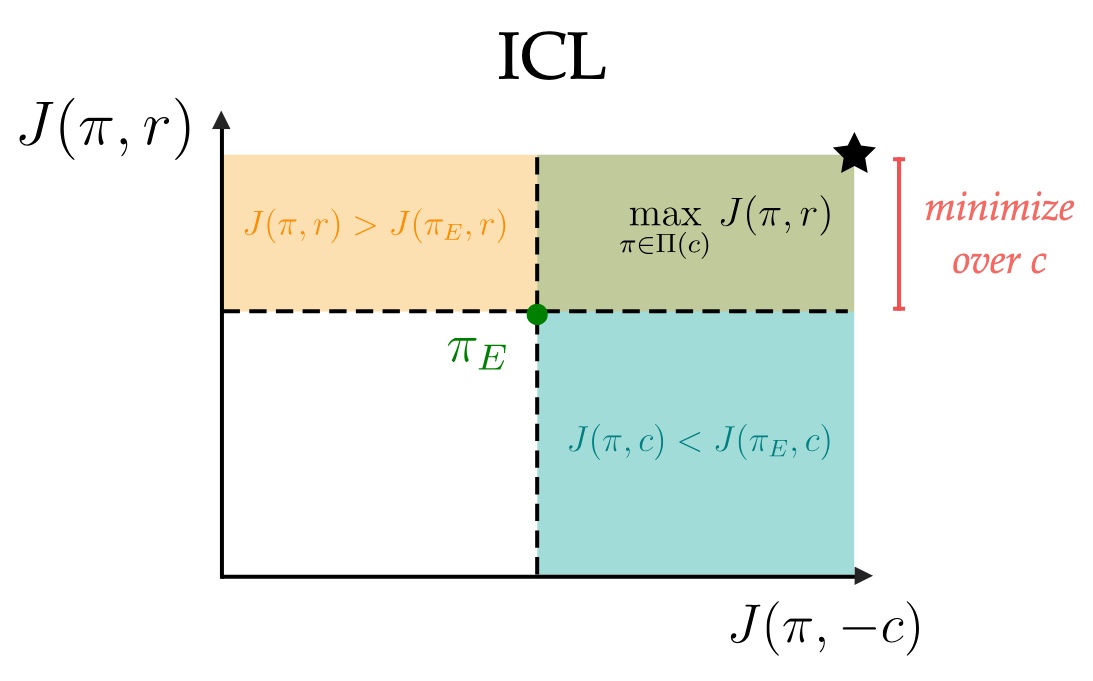
Learning Shared Safety Constraints from Multi-task Demonstrations
Konwoo Kim, Gokul Swamy, Zuxin Liu, Ding Zhao, Sanjiban Choudhury, Steven Wu Advances in Neural Information Processing Systems (NeurIPS), 2023 paper / website MT-ICL learns safety constraints from expert demonstrations across multiple tasks. |
|
|
ManiCast: Collaborative Manipulation with Cost-Aware Human Forecasting
Kushal Kedia, Prithwish Dan, Atiksh Bhardwaj, Sanjiban Choudhury Conference on Robot Learning (CoRL), 2023 paper / website ManiCast learns forecasts of human motions and plans with such forecasts to solve collaborative manipulation tasks. |
|
|
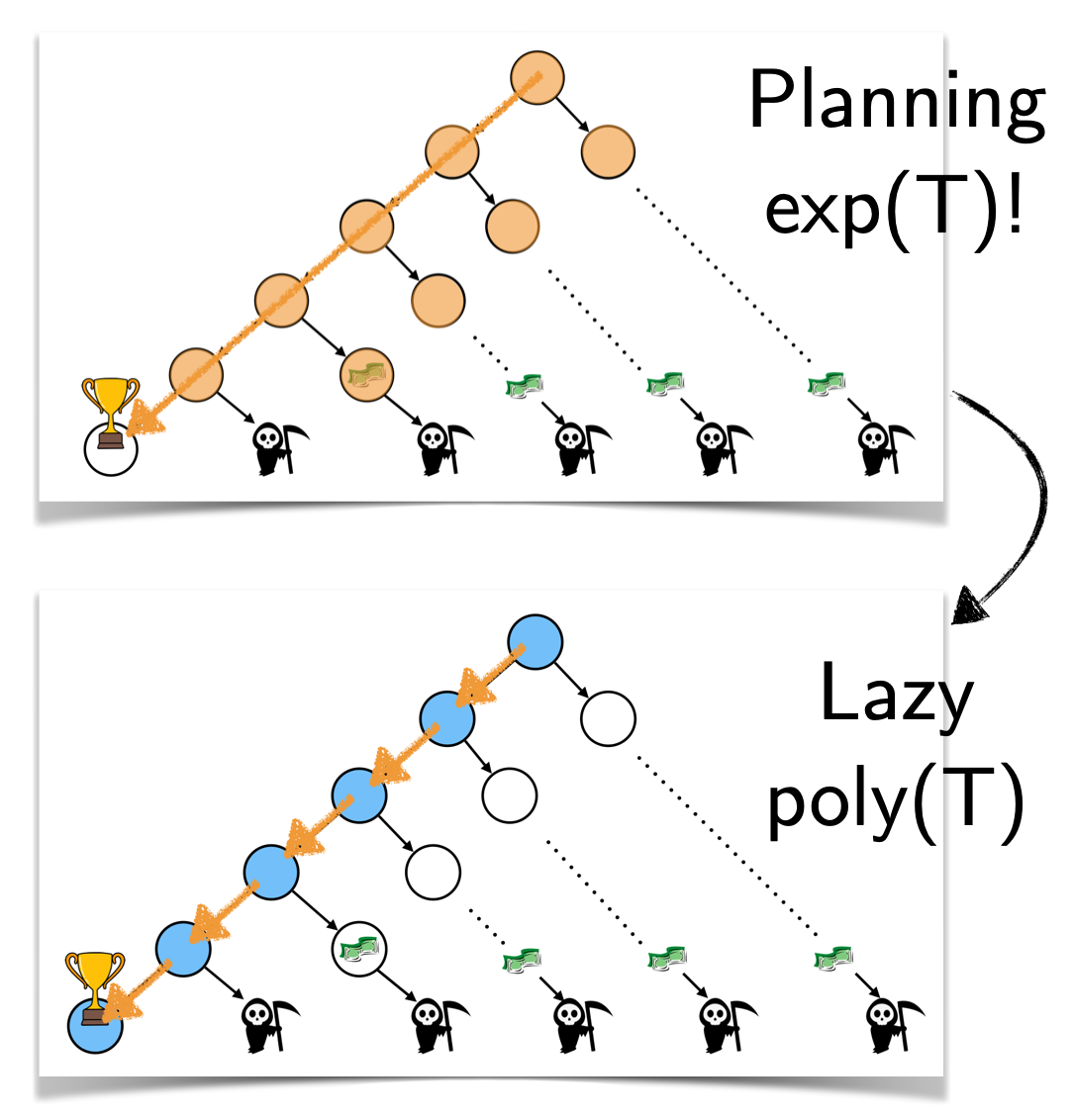
The Virtues of Laziness in Model-based RL: A Unified Objective and Algorithms
Anirudh Vemula, Yuda Song, Aarti Singh, J. Andrew Bagnell, Sanjiban Choudhury International Conference on Machine Learning (ICML), 2023 paper We propose a novel, lazy approach that addresses two fundamental challenges in Model-based Reinforcement Learning (MBRL): the computational expense of repeatedly finding a good policy in the learned model, and the objective mismatch between model fitting and policy computation. |
|
|
Inverse Reinforcement Learning without Reinforcement Learning
Gokul Swamy, Sanjiban Choudhury, J Andrew Bagnell, and Zhiwei Steven Wu International Conference on Machine Learning (ICML), 2023 paper / website We explore inverse reinforcement learning and show that leveraging the state distribution of the expert can significantly reduce the complexities of the RL problem, theoretically providing an exponential speedup and practically enhancing performance in continuous control tasks. |
|
|
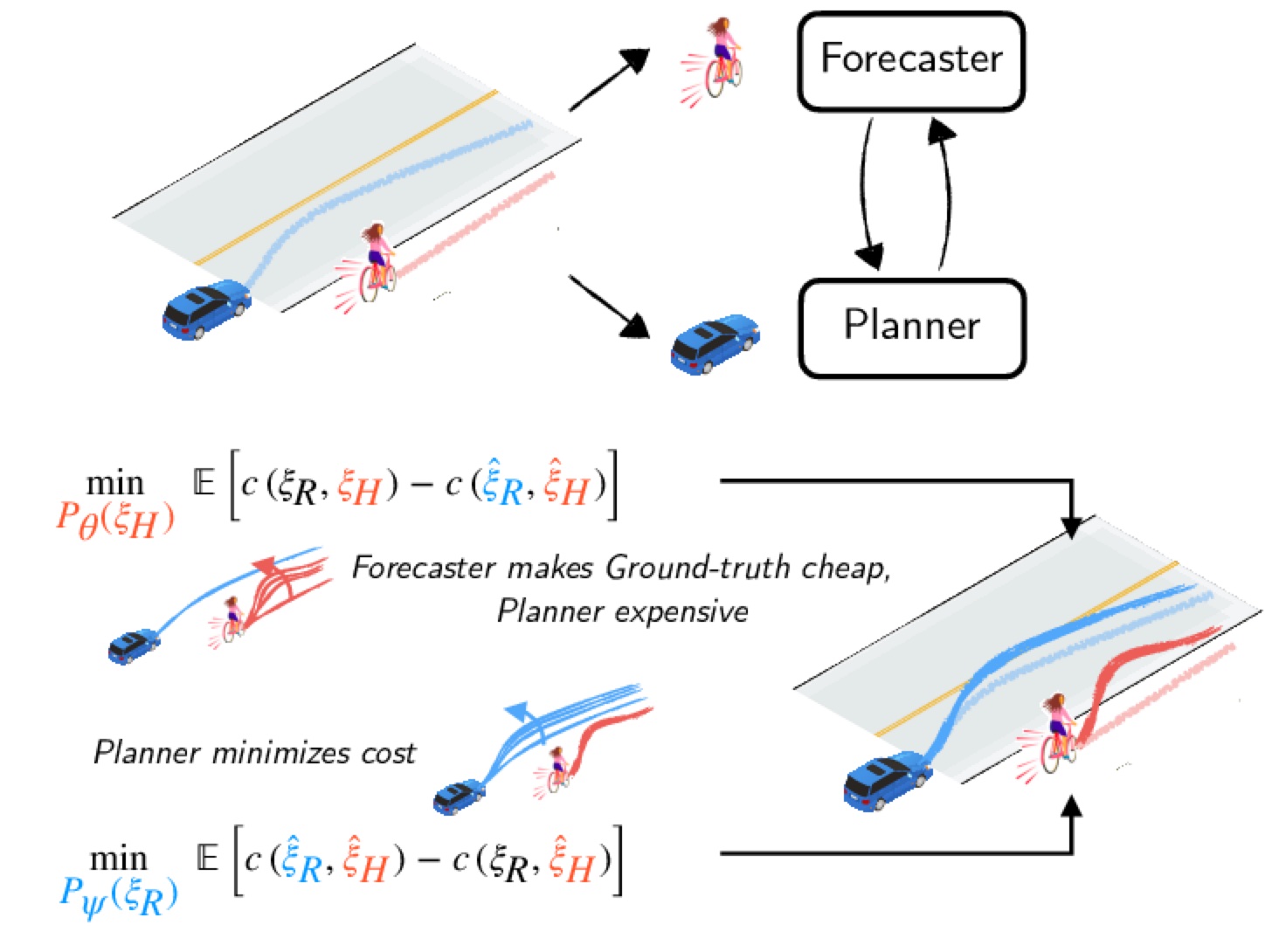
A Game-Theoretic Framework for Joint Forecasting and Planning
Kushal Kedia, Prithwish Dan, Sanjiban Choudhury IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2023 paper / website We propose a novel game-theoretic framework for joint planning and forecasting with the payoff being the performance of the planner against the demonstrator, and present practical algorithms to train models in an end-to-end fashion. |
|
|
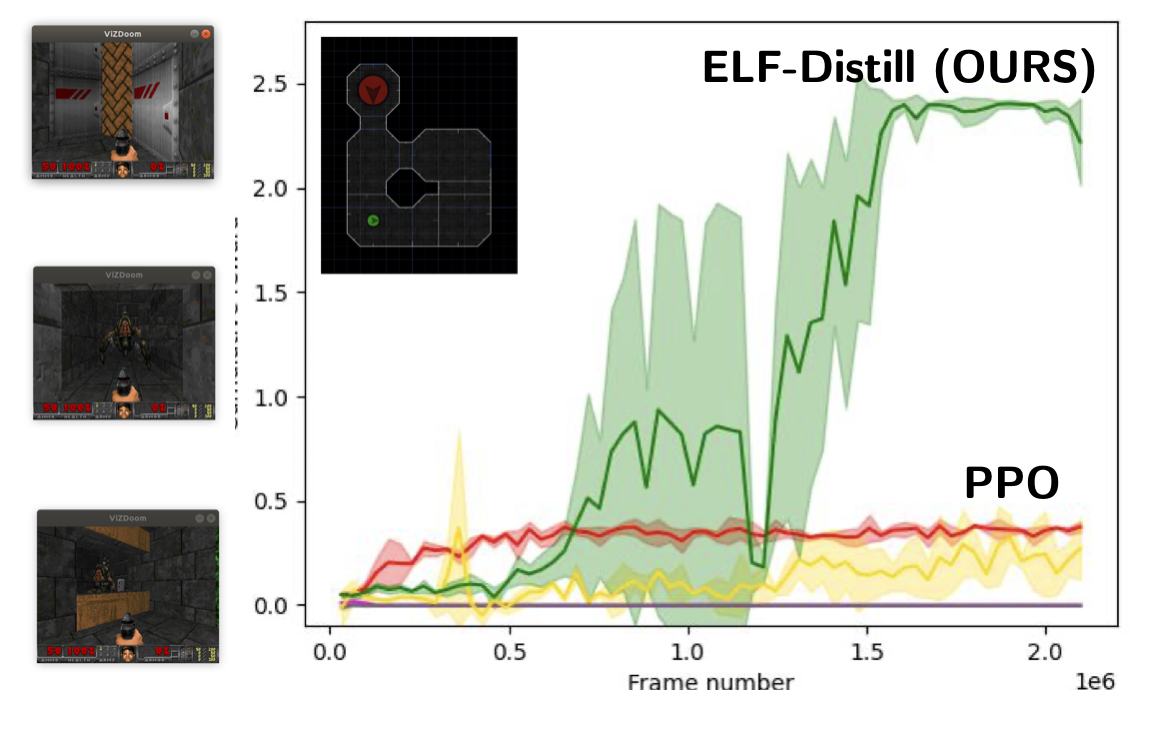
Impossibly Good Experts and How to Follow Them
Aaron Walsman, Muru Zhang, Sanjiban Choudhury, Dieter Fox, Ali Farhadi International Conference on Learning Representations (ICLR), 2023 paper We investigate sequential decision making with "Impossibly Good" experts possessing privileged information, propose necessary criteria for an optimal policy recovery within limited information, and introduce a novel approach, ELF Distillation, outperforming baselines in Minigrid and Vizdoom environments. |
|
|
Sequence Model Imitation Learning with Unobserved Contexts
Gokul Swamy, Sanjiban Choudhury, Zhiwei Steven Wu, and J Andrew Bagnell Advances in Neural Information Processing Systems (NeurIPS), 2022 paper We study imitation learning when the expert has privileged information and show that on-policy algorithms provably learn to recover from their initially suboptimal actions, while off-policy methods naively repeat the past action. |
|
|
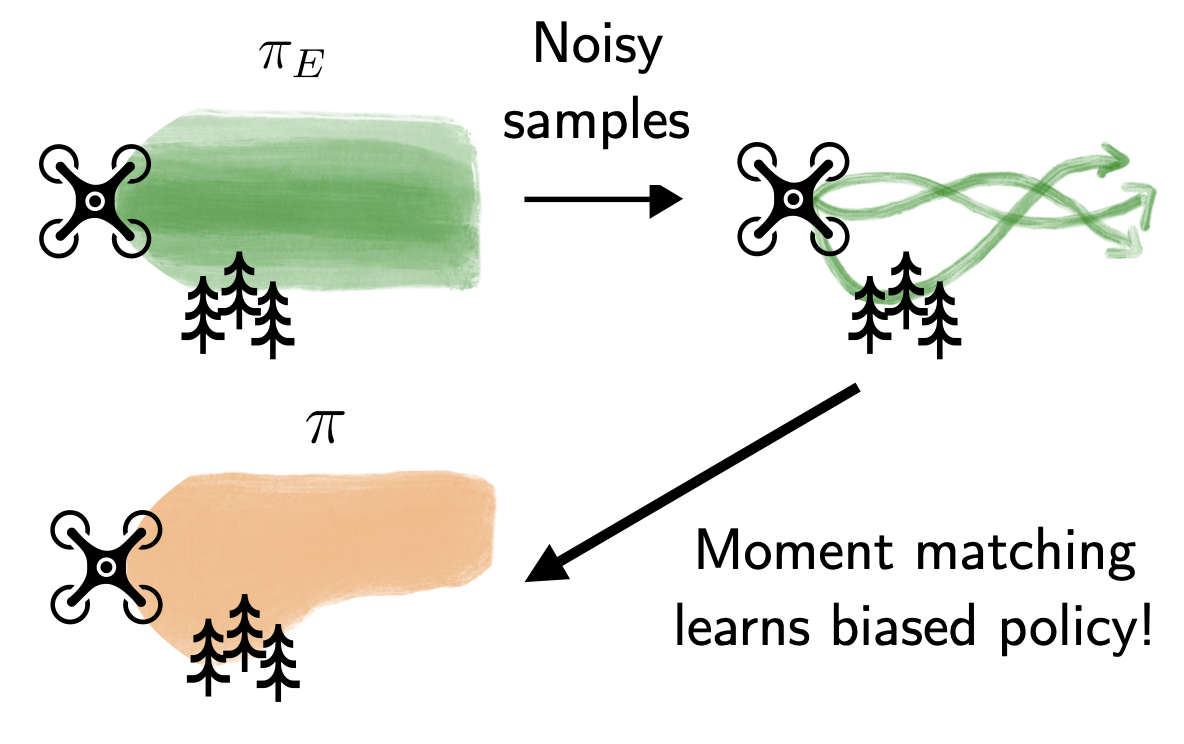
Minimax optimal online imitation learning via replay estimation
Gokul Swamy, Nived Rajaraman, Matt Peng, Sanjiban Choudhury, J Bagnell, Steven Z Wu, Jiantao Jiao, Kannan Ramchandran Advances in Neural Information Processing Systems (NeurIPS), 2022 paper Imitation learning from noisy experts leads to biased policies! Replay estimation fixes this by smoothing the expert by repeatedly executing cached expert actions in a stochastic simulator and imitating that. |
|
|
Towards Uniformly Superhuman Autonomy via Subdominance Minimization
Brian Ziebart, Sanjiban Choudhury, Xinyan Yan, and Paul Vernaza International Conference on Machine Learning (ICML), 2022 paper We look at imitation learning where the demonstrators have varying quality and seek to induce behavior that is unambiguously better (i.e., Pareto dominant or minimally subdominant) than all human demonstrations. |
|
|
Of Moments and Matching: Trade-offs and Treatments in Imitation Learning
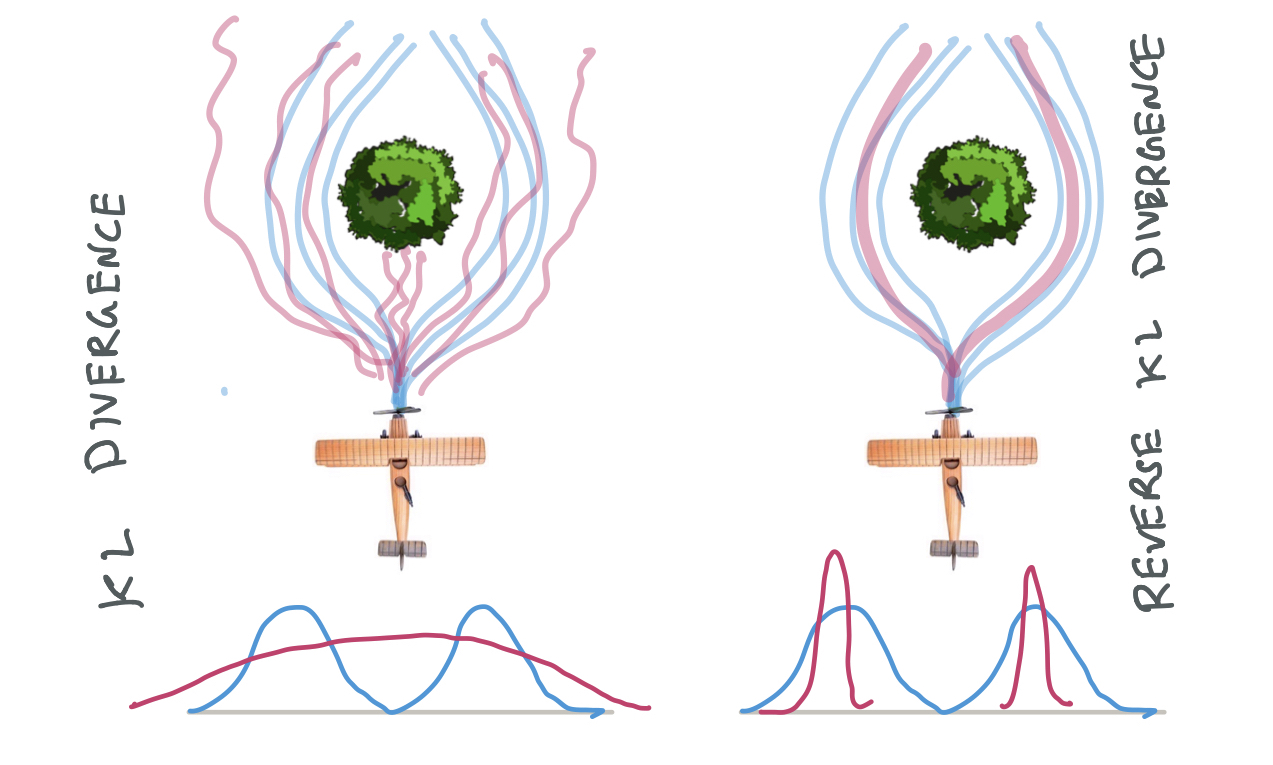
Gokul Swamy, Sanjiban Choudhury, Zhiwei Steven Wu, and J Andrew Bagnell International Conference on Machine Learning (ICML), 2021 paper / website / All of imitation learning can be reduced to a game between a learner (generator) and a value function (discriminator) where the payoff is the performance difference between learner and expert. |
|
|
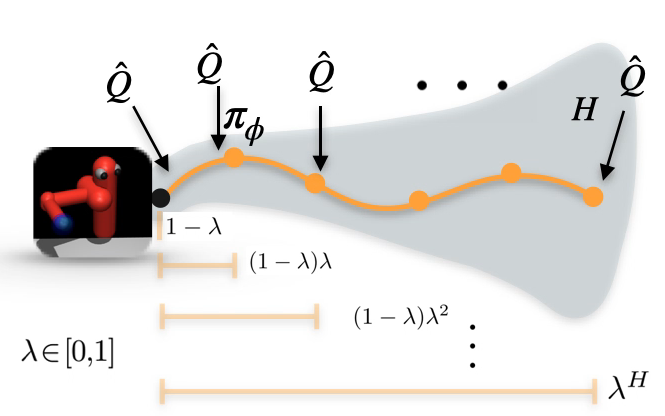
Blending MPC & Value Function Approximation for Efficient Reinforcement Learning
Mohak Bhardwaj, Sanjiban Choudhury, and Byron Boots International Conference on Learning Representations (ICLR), 2021 paper Blend model predictive control (MPC) with learned value estimates to trade-off MPC model errors with learner approximation errors. |
|
|
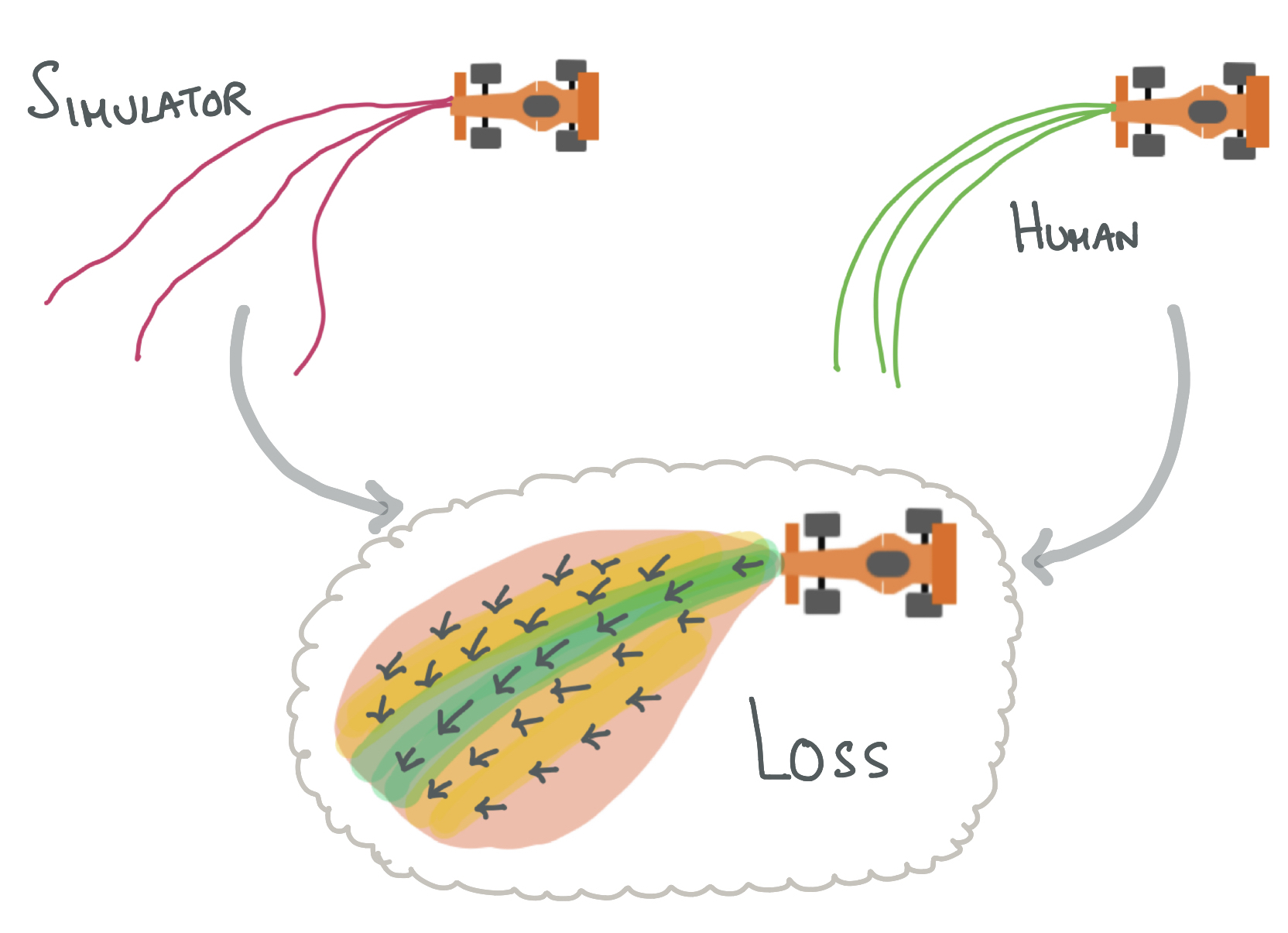
Feedback in Imitation Learning: The Three Regimes of Covariate Shift
Jonathan Spencer, Sanjiban Choudhury, Arun Venkatraman, Brian Ziebart, and J Andrew Bagnell arXiv preprint arXiv:2102.02872, 2021 paper / talk Not all imitation learning problems are alike -- some are easy (do behavior cloning), some are hard (call interactive expert), and some are just right (just need a simulator). |
|
|
Bayesian Residual Policy Optimization: Scalable Bayesian Reinforcement Learning with Clairvoyant Experts
Gilwoo Lee, Brian Hou, Sanjiban Choudhury and Siddhartha S. Srinivasa IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021 paper / talk In Bayesian RL, while solving the belief MDP is hard, solving individual latent MDP is easy. Combine value functions from each MDP along with a learned residual belief policy. |
|
|
Imitation Learning as f-Divergence Minimization
Liyiming Ke, Sanjiban Choudhury, Matt Barnes, Wen Sun, Gilwoo Lee and Siddhartha Srinivasa Workshop on the Algorithmic Foundations of Robotics (WAFR), 2020 paper Many old (and new!) imitation learning algorithms are simply minimizing various f-divergences estimates between the expert and the learner trajectory distributions. |
|
|
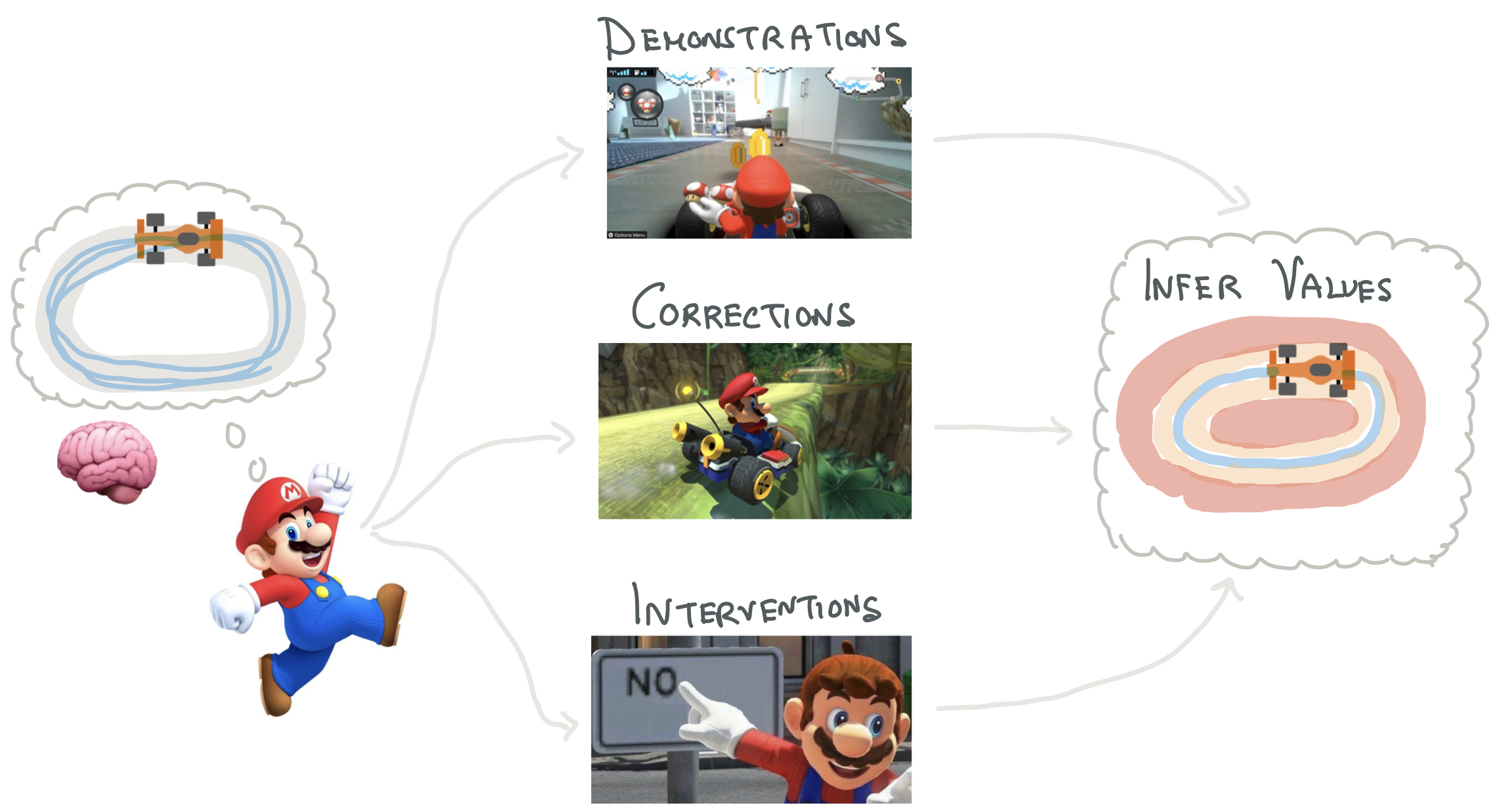
Learning from Interventions: Human-robot interaction as both explicit and implicit feedback
Jonathan Spencer, Sanjiban Choudhury, Matt Barnes and Siddhartha Srinivasa Robotics: Science and Systems (RSS), 2020 paper / talk How can we learn from human interventions? Every intervention reveals some information about expert's implicit value function. Infer this function and optimize it. |
|
|
Learning Online from Corrective Feedback: A Meta-Algorithm for Robotics
Matthew Schmittle, Sanjiban Choudhury, and Siddhartha Srinivasa arXiv preprint arXiv:2104.01021, 2020 paper We can model multi-modal feedback from human (demonstrations, interventions, verbal) as a stream of losses that can be minimized using any no-regret online learning algorithm. |